


AI didn’t arrive overnight. The field spent decades in the valley before climbing back out. Understanding where we came from explains why the present moment is actually different.

We’re Going to Solve Thinking (1950s–1970s)
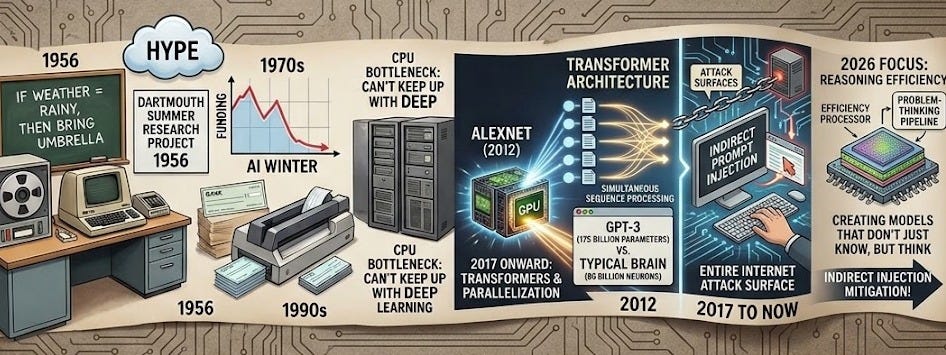
In 1956, researchers at Dartmouth Summer Research Project coined the term “artificial intelligence.” They were optimistic—maybe too optimistic. The idea was that you could program a computer to reason like a human: give it rules and logic, and it would solve problems.
This “symbolic AI” approach ruled for decades. Engineers would manually write rules: if X, then Y. If the weather is rainy, then bring an umbrella. Simple. Clean. Wrong about almost everything complex.
By the 1970s and 1980s, reality had landed hard. The systems couldn’t handle the messiness of real data. They broke on edge cases. Funding evaporated. This first “AI winter” lasted years—not because the researchers were incompetent, but because the promise had outrun the technology.
The lesson: Hype without compute is just noise.
The Rise and Stall of Statistical Learning (1980s–2000s)
The field pivoted. Instead of hand-coding rules, why not let data teach the system? This was the birth of machine learning, statistical methods capable of learning patterns from examples.
By the 1990s and 2000s, these methods worked. Banks deployed neural networks to read handwritten checks. Spam filters learned what junk email looked like. Kaggle competitions crowned winners with algorithms called Gradient Boosting Machines (GBMs), statistical models that combined weak predictors into strong ones.
But progress stalled again. These methods were narrow: a model trained to recognize faces couldn’t suddenly translate English. Each task needed its own hand-engineered pipeline. The systems were brittle.
This wasn’t hype this time—the math worked. The problem was computing. Good statistical learning needs a lot of data, but good deep learning needs vastly more. CPUs couldn’t keep up.
The Deep Learning Inflection: 2012 and Beyond
Then GPUs happened.
In 2012, a team used graphics processors (hardware originally designed for video games) to train a deep neural network on image recognition. The network was called AlexNet. It crushed the competition, cutting error rates nearly in half. The jump was so large that the field collectively paused and said, “Oh. That’s what we’ve been waiting for.”
Deep learning worked because it scaled. More layers, more parameters, more compute. And crucially, with enough data and enough compute, you didn’t need engineers to hand-craft features. The network learned what to look for.
By the mid-2010s, deep learning was everywhere: computer vision, speech recognition, and machine translation.
Researchers noticed something: a new architecture called Transformers (introduced in a 2017 paper titled “Attention Is All You Need”) worked even better. Unlike previous models that read text one word at a time from left to right, Transformers could process entire sequences simultaneously. This "parallelization" allowed them to handle massive datasets with incredible speed, forming the technical foundation for everything that came next.
The Large Language Model Era: 2020 to Now
Starting in 2020, companies began scaling Transformer networks to absurd sizes. OpenAI’s GPT-3, released in 2020, had 175 billion parameters—numbers representing learned patterns. For context: a typical brain has about 86 billion neurons. GPT-3 wasn’t a brain, but it was scaled to a similar order of magnitude.
Then ChatGPT launched in late 2022. It was a GPT-3 variant, fine-tuned to answer questions in conversational English. It hit 1 million users in five days.
Since then: Claude (Anthropic), Gemini (Google), and countless others. The pattern is consistent: scale up, add more compute, train on more text, get smarter.
Why Now Is Actually Different
Here’s what matters: compute is the through-line. AI winters happened when promises exceeded compute capacity. Algorithms didn’t improve miraculously in 2012; GPUs made existing algorithms finally viable.
In 2019, researcher Richard Sutton summarized this shift in an essay titled “The Bitter Lesson.” His point was a blow to human ego: general methods that leverage massive computing always beat “clever” approaches where humans try to bake their own knowledge into the system. The field spent 70 years trying to be smart; it turns out that being “big” was the more effective strategy.
This is why 2020–2025 feels different: we have the compute. We understand the architecture. We have enough data. The constraint that killed AI twice before,” we don’t have enough resources to make this work,” has lifted.
The Cost of Progress: New Vulnerabilities
Each wave of AI introduced new security surfaces. Symbolic AI could fail in obvious ways. Statistical models were opaque but narrowly scoped. Deep learning is opaque and scaled to billions of parameters.
A model file containing billions of learned weights is now the system. Because these systems are pattern-matchers rather than reasoners, they lack an internal “truth check.” This has led to vulnerabilities such as Prompt Injection, in which a model is tricked into ignoring its safety guidelines. As we head into 2026, the threat has evolved into Indirect Prompt Injection, in which an AI can be subverted simply by reading a malicious website or document, turning the entire internet into a potential attack surface.
The attack surfaces keep evolving. So does the defense.
The Actual Arc
The 70-year history of AI is not a genius suddenly striking. It’s: promise, failure, reset, waiting for hardware, breakthrough, scale, repeat. Three phases: symbolic logic failed. Statistical learning stalled. Deep learning accelerated.
We’re in the deep learning phase now, and the resources have finally aligned. But the story isn’t over. As we move through 2026, the focus is shifting from raw scaling to reasoning efficiency, creating models that don’t just know everything, but can “think” through a problem before they speak. The next chapter isn’t just about more data; it’s about what we do with the intelligence we’ve finally managed to build.