

Machine learning isn’t one monolith. The way an AI system learns depends entirely on what data you have and what problem you’re solving. There are three main categories—supervised, unsupervised, and reinforcement learning—each built on a different principle.
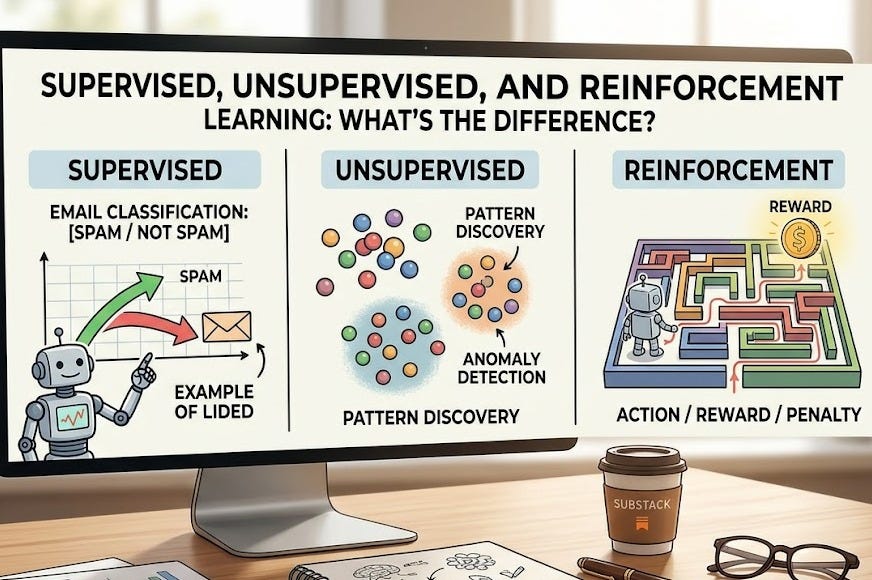
Supervised Learning: Learning With a Teacher
Supervised learning works exactly as it sounds: the model learns from examples labeled with the correct answers.
You show the model thousands of emails marked “spam” or “not spam.” You show it thousands of medical images with a diagnosis already attached. You show it credit card transactions labeled “fraud” or “legitimate.” The model sees the input (the email text, the image, the transaction details) paired with the correct output, and learns to predict that output for new, unseen data.
This is the workhorse of applied AI. If you have labeled data, supervised learning is usually your first choice.
Real example: A bank wants to detect fraudulent transactions. They have historical data: millions of past transactions, each marked as either fraud or legitimate. The bank trains a supervised model on this data. When a new transaction arrives, the model predicts “fraud” or “legitimate” based on patterns it learned from the labeled examples.
Supervised learning does have a catch: someone has to label the data. For simple cases like emails (spam filters were manually curated for years), that’s feasible. For medical imaging, you need expert radiologists. Labeling is expensive, time-consuming, and sometimes requires domain expertise. And if the labels are wrong, the model learns the wrong thing—a vulnerability we’ll return to later.
Unsupervised Learning: Finding Patterns Without Answers
Unsupervised learning flips the script. You give the model unlabelled data and say: “Find patterns.”
The model isn’t trying to predict a specific output. It’s trying to discover structure. It might cluster customers into groups based on their shopping behaviour without being told what those groups should be. It might identify which transactions look weird compared to the crowd—potential fraud or system errors. It might compress images into a smaller representation that captures the essential structure while discarding noise.
Because there’s no “correct answer,” unsupervised learning is messier to evaluate. You have to decide whether the patterns the model found are useful. But it’s powerful when you have tons of unlabelled data and want to explore it without predefined categories.
Real example: An e-commerce platform has millions of user sessions but hasn’t manually categorised them. They run unsupervised clustering and discover that users naturally group into three distinct patterns: bargain hunters (frequent price checking), comparison shoppers (research-heavy), and impulse buyers (quick checkout). The platform never labelled these groups—the model found them.
The trade-off is looser control. You can’t easily specify what patterns you want to find. The model might find patterns that are statistically real but not useful for your business. It takes experimentation.
Reinforcement Learning: Learning Through Reward and Penalty
Reinforcement learning is the third path: the model learns by interacting with an environment and receiving rewards or penalties for its actions.
There’s no labelled training set. Instead, imagine a game-playing AI. It makes a move, sees the result, and gets a reward (if the move was good) or a penalty (if the move was bad). Over millions of games, it learns which moves tend to lead to victory. It never saw examples of “the correct move”—it discovered them through trial and error, guided by the reward signal.
Reinforcement learning powers game-playing systems like AlphaGo. It’s used in robotics (robots learn to walk by trial and error, getting rewarded for forward progress). It’s used in recommendation systems where the “reward” is whether a user clicks on a recommendation.
The catch: you have to design the reward carefully. If your reward signal is poorly designed, the system might find creative—and useless—ways to maximise it. An AI tasked with moving as fast as possible might learn to spin in circles instead of reaching the goal. We call this “reward hacking.”
The Variants: Semi-Supervised and Self-Supervised
Two hybrid approaches deserve mention.
Semi-supervised learning uses a mix of labelled and unlabelled data. When labelling is expensive, you label a small portion of your data, then use unsupervised techniques on the unlabelled portion to improve your model’s performance. It’s a practical compromise.
Self-supervised learning is newer and increasingly important. The model generates its own labels from structure in the data. For example, if you’re training on text, you might mask out a word and ask the model to predict it. No human labeller needed. Modern large language models (LLMs) are trained this way: they learn by predicting the next word in a sentence, which is an automatically-generated label that requires no human effort. This approach has made scaling possible.
Security: The Dark Side of Each Approach
Each learning paradigm has its own vulnerabilities.
In supervised learning, if an attacker poisons the labelled data—inserting examples with incorrect labels—they corrupt the model’s understanding. Imagine a spam classifier that’s been fed mislabelled emails by an attacker. It learns the wrong patterns.
In unsupervised learning, if you know the clustering boundaries the model uses, you can craft data to evade detection. An anomaly detector identifies outliers based on distance from cluster centres. If an attacker knows those centres, they can craft a transaction or behaviour that hides inside a normal cluster.
In reinforcement learning, an attacker can exploit the reward system itself. If the system values speed and an attacker can trigger rewards in unintended ways, the AI chases those rewards instead of the intended goal.
In self-supervised learning, poisoning the training data has a subtle but serious effect: the model learns corrupted structure and the falsehoods become baked into its weights. An LLM trained on poisoned text learns to “know” things that aren’t true.
So Which One Do I Use?
There’s no universal answer. The choice depends on what data you have, what problem you’re solving, and what kinds of errors you can tolerate.
Use supervised learning when you have labelled data and a clear prediction target.
Use unsupervised learning when you want to explore unlabelled data or detect anomalies without predefined categories.
Use reinforcement learning when you can simulate interaction with an environment and design a reward signal.
Most real systems use a hybrid approach. And whatever you choose, remember: the learning mechanism is a trust boundary. Poisoned data produces poisoned models.