

What are embeddings? They’re the bridge between human meaning and machine computation — and without them, modern AI wouldn’t exist.
You’ve probably heard that AI systems understand language. They don’t, not really. What they actually do is convert language into numbers, and then they work with those numbers. That conversion process is where embeddings come in.
The Problem With Text
Computers don’t think in words. They think in numbers. If you want an AI system to do anything useful with language, you first have to translate text into a numerical format it can process.
The early solution was crude. In the 1960s and beyond, AI researchers used something called one-hot encoding. Here’s how it worked: take every unique word in your vocabulary, assign it a number, then represent each word as a massive vector (a list of numbers) filled mostly with zeros.
For example, if your vocabulary had 10,000 words, the word “cat” might be represented as a list with 10,000 slots—9,999 zeros and a single 1 in the position for “cat”. Everything else was zeros.
This worked. It was also useless for anything interesting. The problem: one-hot encoding has no notion of meaning. The vector for “cat” is completely unrelated to the vector for “kitten” or “pet”. To the computer, they’re just arbitrary coordinates in space, no more connected than “cat” and “refrigerator”.
Embeddings solved this problem.
What Is an Embedding?
An embedding is a compact, dense list of numbers — meaning mostly non-zero, packed with information rather than filled with zeros — that represents the meaning of something: a word, a phrase, an image. Instead of 10,000 slots with mostly zeros, an embedding might be 300 or 1,536 numbers. Each number is non-zero and learned from data.
Here’s the key insight: embeddings are learned by watching patterns in real text. The most famous early approach was Word2Vec, created in 2013. Word2Vec learned embeddings by looking at which words appeared near each other in massive amounts of text. Words that appeared in similar contexts got embeddings that were numerically close to each other.
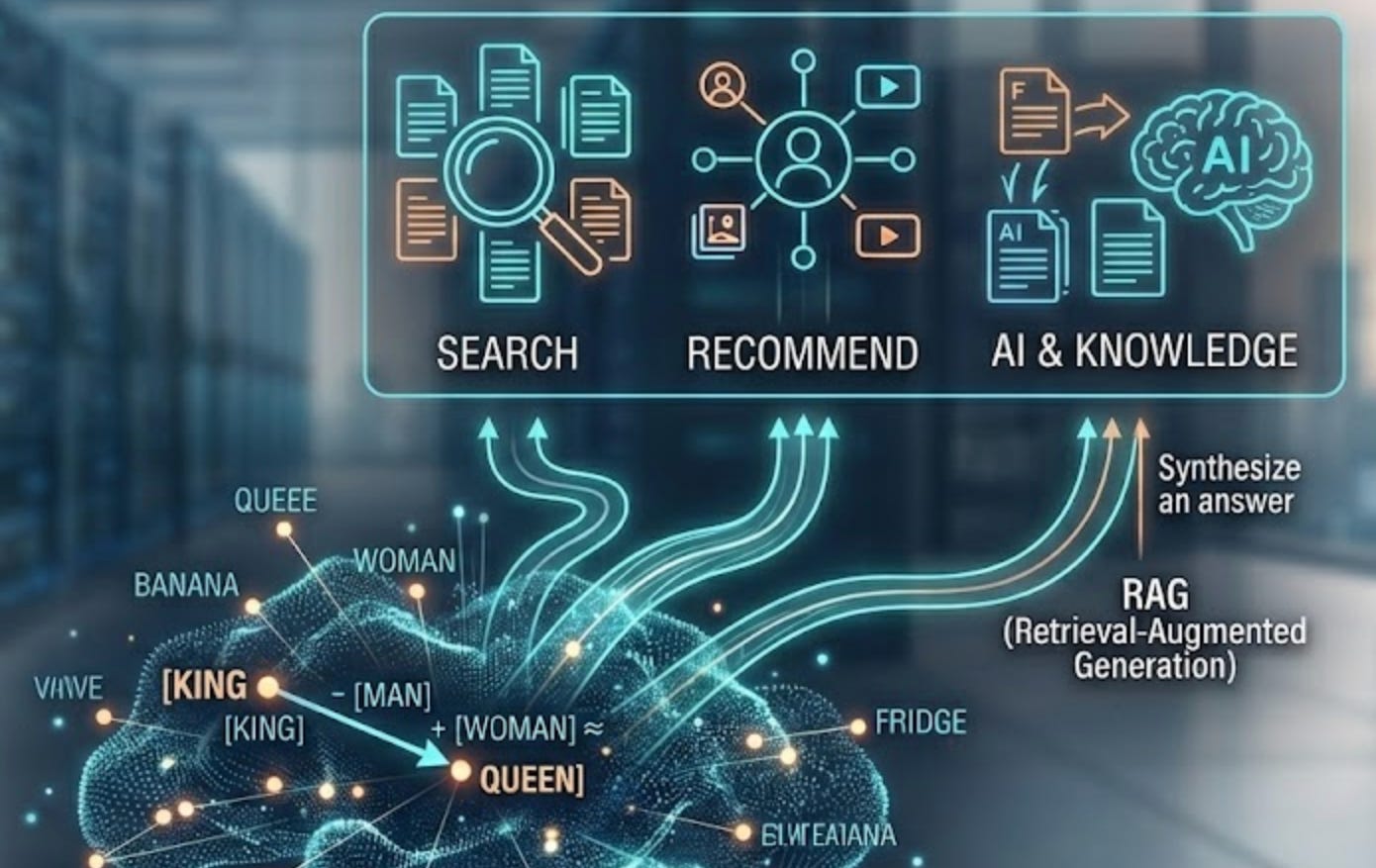
This created something almost magical: words with related meanings naturally ended up near each other in the numerical space. “King” and “queen” had similar embeddings. “Banana” and “king” did not. The computer never saw a rule saying “these words are related”—it inferred it purely from patterns.
You can even do arithmetic with embeddings:
king − man + woman ≈ queen(Each word is represented as its embedding vector, and you’re literally adding and subtracting lists of numbers.)
This isn’t a trick. It’s evidence that embeddings capture semantic structure—the meaning relationships between words.
One Word, Many Embeddings
Modern AI systems like ChatGPT use something more sophisticated: contextual embeddings. The difference is subtle but important.
In Word2Vec, the word “bank” always had the same embedding. But “bank” in “I sat by the river bank” carries a different meaning than “bank” in “I have money in my bank account”. A contextual embedding system understands this. It generates different embeddings for the same word depending on the surrounding context.
This is closer to how humans actually work. You don’t know what a word means in isolation; you know it from the words around it.
What Are Embeddings Actually For?
The main jobs embeddings do:
Semantic search: You have a collection of documents stored as embeddings. Someone searches for “how do I fix a leaky faucet?” You convert that query to an embedding, find the embeddings in your database that are numerically closest to it, and return those documents. The computer found relevant results without using keyword matching.
Recommendation systems: An embedding represents a movie, a product, a song. Users who liked similar items have their preferences mapped to similar regions in embedding space. The system recommends items that are close to what they already like.
Retrieval-Augmented Generation (RAG) is increasingly common in modern AI. Instead of forcing an LLM to memorize everything, you store facts as embeddings in a searchable database. When a user asks a question, you:
Convert the question to an embedding
Search the database for relevant documents (embeddings that are numerically close)
Inject those documents into the prompt
Let the LLM answer using the retrieved facts
This reduces hallucinations—the tendency for LLMs to confidently state false information. You’re giving it actual sources to cite.
The Security Problem Nobody Talks About
Embeddings are useful. They’re also a risk.
Embedding inversion attacks: Security researchers have shown it’s possible to partially reconstruct the original text from its embedding. If you publish embeddings of sensitive documents, an attacker might be able to reverse-engineer what those documents said. It’s not perfect reconstruction, but it works often enough to be a privacy concern.
Poisoned embeddings: If someone compromises the embedding model itself, they can make the system consider completely unrelated documents as “similar”. An attacker controls what “relevant” means. A search for “safe coding practices” might return malicious documentation instead.
RAG poisoning: If you’re using RAG to retrieve documents from a database, an attacker who can inject malicious documents into that database becomes powerful. Those documents get retrieved, fed into the LLM’s prompt, and influence its output. The LLM trusts them because they were supposedly “relevant”.
None of these attacks is theoretical. They’ve been demonstrated in research. As embeddings become more central to how AI systems work, the attack surface grows.
The Bottom Line
Embeddings are how AI systems convert meaning into mathematics. They’re why modern AI can understand semantic similarity—why it knows “king” is more like “queen” than like “banana”. They’re also why RAG works, why recommendation systems function, why semantic search finds relevant results.
They’re invisible to users but foundational to everything that follows. Understanding them is essential to understanding how modern AI actually works.