

Neural networks are how machines learn patterns. They’re loosely inspired by how your brain works: interconnected nodes (called neurons) pass signals to each other, and those signals get stronger or weaker as the network learns.
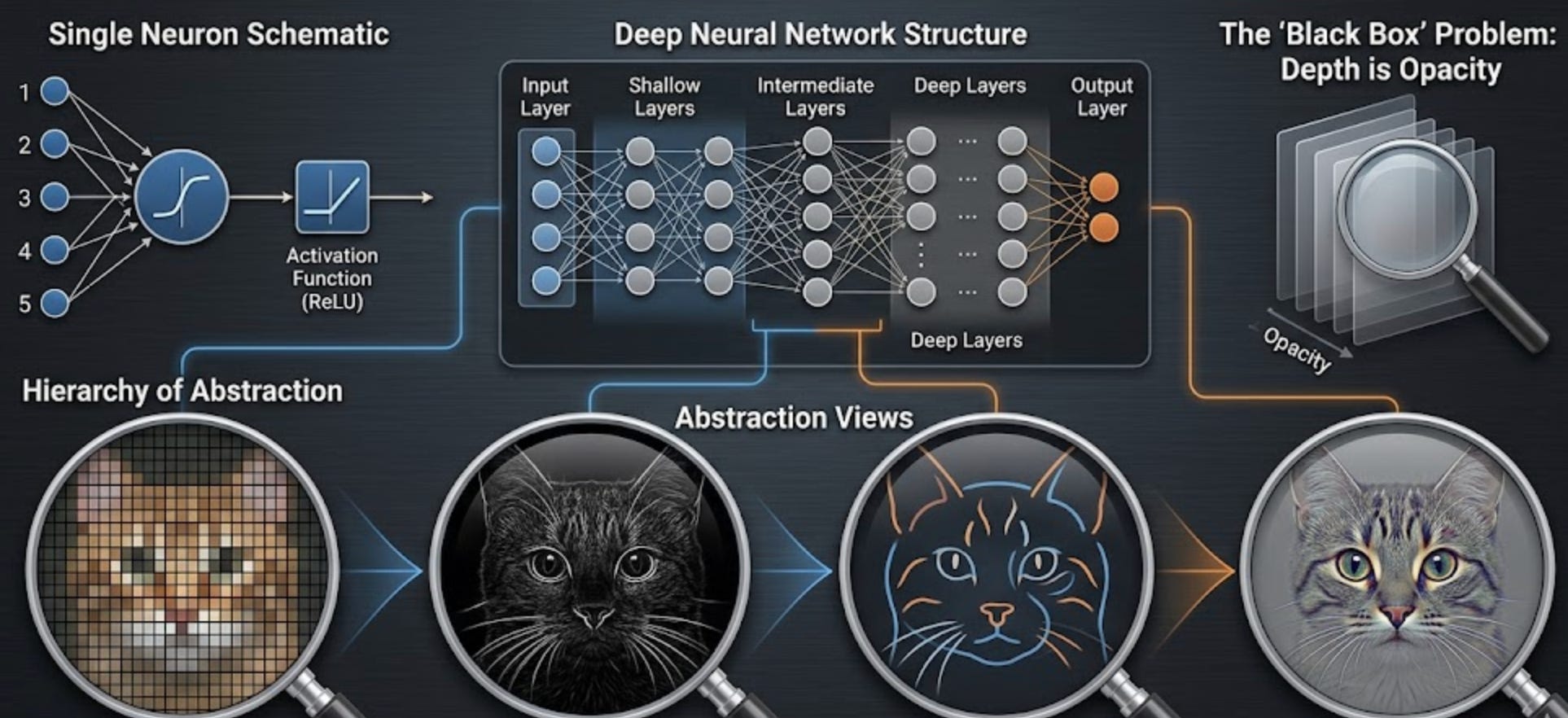
But a single neuron isn’t smart. It’s dumb, actually. It takes some inputs, multiplies each one by a weight (a number that changes during training), sums them up, and then applies an activation function — a mathematical rule that decides whether this neuron ‘fires’ or stays quiet. That firing decision gets passed to the next layer.
Why the activation function? Without it, you’d just have a bunch of math that amounts to a straight line. A line can’t learn anything interesting. The activation function introduces non-linearity — it lets the network bend and twist its decision boundaries to capture complex, messy patterns.
Layers: Input, Hidden, Output
A neural network is organized in layers. Data comes in through the input layer. Then there are one or more hidden layers that perform the actual learning. Finally, the output layer produces the result.
Here’s a concrete example: recognizing handwritten digits. The input layer receives pixel values (0 to 255 for each pixel). Hidden layers find patterns — first noticing edges, then shapes, then features like loops or corners. The output layer produces 10 neurons, one for each digit (0–9), and whichever one fires strongest is the network’s guess.
The magic is that you don’t teach the network “this is what a 3 looks like.” You just show it thousands of examples, let it adjust the weights, and it figures it out on its own.
Why ‘Deep’ Matters
This is where the term deep learning comes in. A “shallow” network has only 1 or 2 hidden layers. A “deep” network has many, sometimes 50, 100, or more.
Why does this matter? Each layer builds on the previous one, creating an abstraction hierarchy. In an image recognition network:
Layer 1 learns edges
Layer 5 learns shapes
Layer 20 learns “cat face.”
You cannot build that hierarchy with a shallow network. A shallow network can only learn simple, direct relationships. To recognize complex things — faces, speech, language — you need depth. Each layer refines what the previous layer learned, building toward increasingly abstract concepts.
This is why depth unlocked progress. In the 1990s, we could effectively train only shallow networks. Once we figured out how to train deep networks (around 2012), the results skyrocketed.
Specialized Architectures Encode Assumptions
Not all networks are the same shape. Some are specialized for specific tasks because they encode assumptions about the data.
Convolutional Neural Networks (CNNs) are built for images. They use sliding filters that scan across an image to detect spatial patterns. The assumption is simple: nearby pixels relate to each other. A CNN learns that a cat’s ear has a specific texture, and that texture lives next to the cat’s head.
CNNs have been deployed in US banking since 1996 to read checks automatically — they identify account numbers, routing numbers, and amounts faster and more reliably than humans. That’s not recent tech. It’s been working for three decades.
The architecture itself encodes what matters. CNNs assume spatial locality. Transformers (which we cover in the next post—the architecture behind ChatGPT) assume that relationships between words matter more than their positions. RNNs (Recurrent Neural Networks — an older approach that processes words sequentially, one at a time) assume order is everything. The architecture is a bet about the structure of the problem.
The Black Box Problem: Depth Is Opacity
Here’s a security problem that scales with depth: a 50-layer network’s decisions cannot be traced back through each layer by a human. You can’t inspect layer 25, see what it learned, and explain “this is why the model chose that output.”
This is the black box problem. It’s not just a UX inconvenience. It’s a security property. If you can’t explain why a model made a decision, you can’t audit it, you can’t catch when it’s wrong in dangerous ways, and you can’t defend it reliably.
As networks get deeper (and larger), this opacity gets worse. This matters when the model’s decisions have real stakes — medical diagnosis, loan approval, criminal risk assessment.
Emergent Behaviors at Scale
One more thing: emergent behaviors appear at scale. These are capabilities that weren’t present in smaller versions of the same architecture but suddenly show up in larger ones.
GPT-2 (1.5 billion parameters) couldn’t do arithmetic reliably. GPT-3 (175 billion parameters) could. GPT-4 (much larger) could do it even better. Nobody trained it specifically on arithmetic. The capability emerged from scale.
This is unpredictable and hard to test for. You build a model, scale it up, and suddenly it can do something you weren’t expecting. That’s powerful — but it also means safety testing is harder. You can’t just test a small model and assume the large one will behave the same way.
What Are Neural Networks, Really?
Understanding what neural networks are and why depth matters is the foundation for everything that follows. A single neuron is dumb. A million neurons arranged in 50 layers, trained on billions of examples, produce systems that can recognize faces, translate languages, and generate coherent text. The depth enables the abstraction. The abstraction enables the capability. And the opacity that comes with depth is a security problem we’ll be dealing with for a long time.
In the next post, we’ll look at the specific architecture that powers ChatGPT, Claude, and almost every modern AI system: the transformer.