

An AI model is not software in the way you know software. It’s not a program with if-then statements. It’s a mathematical function with learned parameters—numbers that have been adjusted to recognize patterns in data.
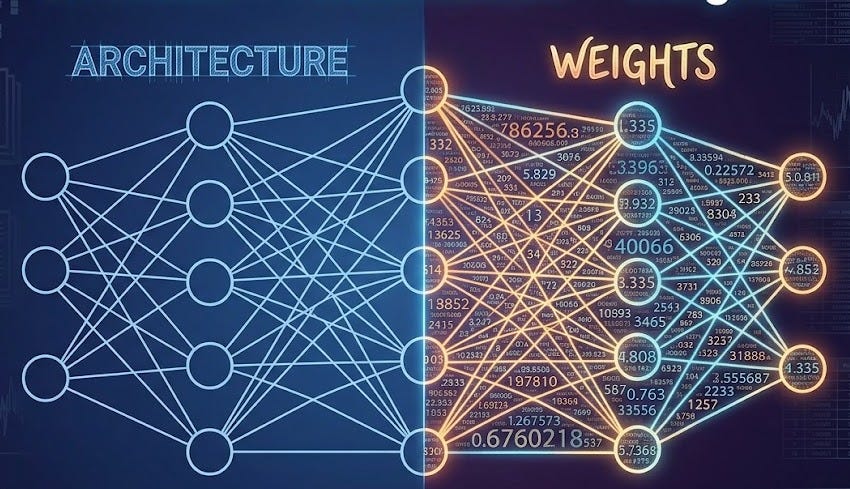
Think of it like this: the architecture is the recipe structure. The weights (learned parameters) are the specific measurements tuned by tasting thousands of dishes.
Model = Architecture + Weights
The architecture is the skeleton—the layers of neurons, the way information flows through the system, and the rules that map inputs to outputs. You define the architecture. It’s the blueprint.
The weights are everything else. They’re numbers—sometimes billions of them. Each weight is a tiny adjustment that helps the model recognize patterns. You don’t define them; training does.
Here’s a concrete example. A simple image classifier might have this architecture:
Input layer (the image pixels)
Hidden layer 1 (256 neurons)
Hidden layer 2 (128 neurons)
Output layer (10 categories: cat, dog, bird, etc.)
The architecture tells you the shape. But there are millions of weights between those neurons. Those weights determine what the model actually “knows.” The same architecture trained on different data will have different weights and behave completely differently.
What a Model Actually Does
A model takes input and produces output. Here are some real examples:
Image model: you feed it a photo → it outputs a label (cat, dog, bird)
Language model: you feed it text → it outputs more text (a completion, an answer, a translation)
Audio model: you feed it sound → it outputs a transcript or classification
Tabular model: you feed it a row of numbers → it outputs a prediction (will this customer churn?)
The model doesn’t “think” in the way humans do. It doesn’t have reasoning or understanding. It’s a statistical function. Given input X, it produces output Y based on patterns it learned from training data.
For a language model like ChatGPT, the input is text. The model predicts the next word based on the previous words. Then it predicts the next word after that. And so on. Each prediction is a probability distribution over possible words.
It sounds simple because it is simple. The magic (and the mystery) comes from scale. Billions of parameters adjusted on trillions of words produce a system that appears to understand language. It’s actually pattern matching at extraordinary scale.
The Model File: Just Weights
When you download or run a model, what you’re actually getting is a file containing all those learned weights. Common formats include .pkl (pickle), .safetensors, .pth (PyTorch), or .bin (HuggingFace).
Inside that file: weights. Billions of decimal numbers. That’s the entire model. The architecture is usually defined separately (in code), but the weights are the actual learned knowledge.
This matters more than you might think. That model file is the system. If someone modifies the weights—even slightly—the model’s behavior changes. If a weight is corrupted, the output becomes unreliable. If a weight is deliberately tampered with, the model can be made to misbehave.
This is why the security of model files matters. An untrustworthy source for a model file is untrustworthy, full stop.
Why Model Files Can Be Dangerous
Pickle files (.pkl) deserve special mention because they can execute code when loaded. This is a legacy of how Python pickle works—it was designed to serialize arbitrary Python objects, including functions. An attacker can craft a malicious pickle file that runs code the moment you load it.
If you download a model in pickle format from an untrusted source and load it, you’re potentially running arbitrary code. Safer formats like .safetensors don’t have this vulnerability; they only contain numbers.
Models Are Not Programs
This is the mental shift that matters. A traditional program has logic you can read: function calls, conditionals, loops. A model has none of that. You can’t open a large language model and read “here’s where it decides whether to be helpful.” The behavior emerges from the weights.
This means:
Models are harder to audit. You can’t trace a decision path like you can in code.
Models are harder to explain. You can’t point to a line and say “this caused the output.”
Models fail in unexpected ways. They don’t fail because of a bug in your if-then logic; they fail because the pattern they learned doesn’t generalize.
The Practical Reality
In practice, when you use ChatGPT or Claude, you’re downloading (or accessing via API) a model file with billions of weights. The companies behind those models spent months training them on massive amounts of text using specialized hardware. Then they saved the weights to a file.
When you type a question, that file (the weights) processes your text through its learned patterns and produces an answer. The answer reflects what the model learned during training, for better and worse.
You’re not running a program. You’re querying a statistical function that’s been tuned to be useful.
What is Next
In the next post, we’ll look at different types of learning: supervised learning (where you have labels), unsupervised learning (where you don’t), and reinforcement learning (where the system learns from rewards and penalties).
For now, the key insight: an AI model is a mathematical function with parameters learned from data. The architecture is the shape. The weights are the knowledge. The model file is the saved state of that knowledge. Understanding this separates mystique from reality.